Codex: The Ultimate Programming Tool of 2026
I have used Codex for three months and truly believe it is the most worthwhile programming tool of 2026, bar none.
Unlike ChatGPT, which is merely a “Q&A robot,” Codex is a complete autonomous agent. You give it a requirement, and it can read code, write code, run tests, and fix bugs without any intervention from you. I had a project that used to take two days to complete; now, with Codex, I can finish it in half an hour.
Even more impressive is its multi-agent mode: you can have several “clones” working on different tasks simultaneously—one checking documentation, another writing code, and another doing code reviews. Running six threads concurrently is more efficient than managing three interns.
However, OpenAI’s pricing strategy can be daunting: the Plus version costs $20/month with strict usage limits, and you can exceed the limit after writing just two medium-sized projects. The Pro version costs $200/month (about 1400 RMB) for unlimited use. For developers in China, there are additional network issues—connecting to api.openai.com is often hit or miss.
While third-party proxies are cheaper, they come with risks, and your code and conversation data all pass through third-party servers—would you feel comfortable sending your core business logic to someone else?
Is there a solution that doesn’t require a subscription, doesn’t involve sending code to third parties, and allows Codex to run perfectly?
Yes. And for Apple Silicon users, the experience is fantastic.
The answer is: Local Large Models + Codex. Completely free, fully offline, and entirely private.
Here’s a tutorial to get you set up in just 10 minutes.
Why Local Large Models Can Be Used with Codex
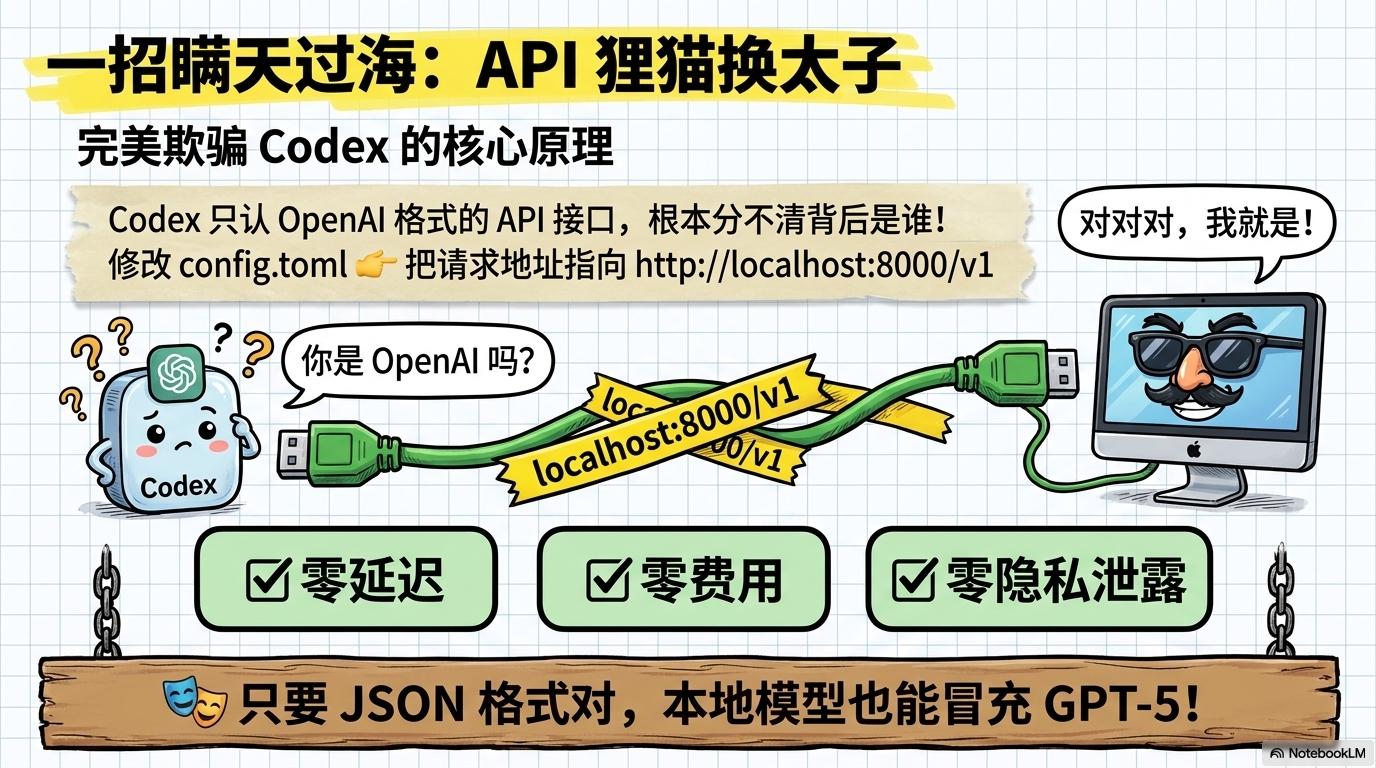
The core principle is the same as connecting to a third-party API: Codex only recognizes OpenAI formatted API interfaces.
Whether the backend is OpenAI’s GPT-5, a third-party proxy, or a large model running locally on your Mac, as long as the API request and response JSON formats are compatible, Codex cannot tell the difference.
Your request flow comparison:
Codex App → api.openai.com → OpenAI server (Official, $200/month)
Codex App → Proxy Address → OpenAI server (Proxy, cheaper but risky)
Codex App → localhost:8000 → Your Mac local model (Local, free + private)
In Codex’s configuration file config.toml, there is a parameter called openai_base_url. After setting it, all requests will be sent to your specified address.
Point it to http://localhost:8000/v1, and Codex will communicate with the large model running on your Mac. Zero latency, zero cost, zero privacy leaks.
Prerequisites

You need to meet two conditions:
- A Mac with Apple Silicon (M1/M2/M3/M4 series)
- Recommended 24GB or more RAM (16GB can only run 7B-14B models, 8GB has a poor experience)
- Codex itself also occupies memory, so 8GB is basically insufficient
- If memory is insufficient, you can consider using a third-party API proxy solution, spending $20 to use GPT-5, which has no hardware requirements
- Codex App must be installed (desktop version, not the web version)
If your Mac meets the conditions, congratulations—you already have an “AI programming supercomputer” in your hands, just waiting to be activated.
Choosing a Local Large Model Inference Tool

Apple Silicon users have three mainstream choices, ranked by recommendation:
Option 1: MLX (omlx) — Apple Native, Best Performance ⭐ Recommended
MLX is Apple’s official machine learning framework, optimized for Apple Silicon. omlx is a model inference server based on MLX, providing a fully compatible OpenAI API interface.
Advantages:
- Official Apple framework with the highest GPU acceleration efficiency
- Supports 4bit/8bit quantization, smoothly running 27B level models with 24GB RAM
- Ready to use; just one command after pip install
Installation:
pip install omlx
omlx serve
After starting, it provides API services at http://localhost:8000 by default.
omlx includes model download management, automatically pulling the default model (Qwen3.6-27B-4bit, about 14GB) on the first startup.
Option 2: Ollama — Cross-Platform, Richest Ecosystem
Ollama is currently the most popular local large model running tool, supporting Mac/Windows/Linux.
Advantages:
- The richest model library, download models with ollama pull
- Active community with comprehensive documentation
- Cross-platform, usable by Windows users as well
Installation:
# On Mac, you can use Homebrew
brew install ollama
ollama serve # Start the service, default port 11434
ollama pull qwen3.6 # Download the model
Ollama’s default port is 11434, so make sure to change the port number when configuring Codex.
Option 3: LMStudio — Graphical Interface, Most User-Friendly
LMStudio provides a complete GUI interface, suitable for users who prefer not to use the command line.
Advantages:
- Graphical interface for managing models, easy to download, load, and unload
- Built-in local chat interface to experience model effects first
- One-click to start the local API server
Installation: Visit the LMStudio official website to download and install. After starting, click on “Local API Server” on the left side.
Step-by-Step Configuration of Codex
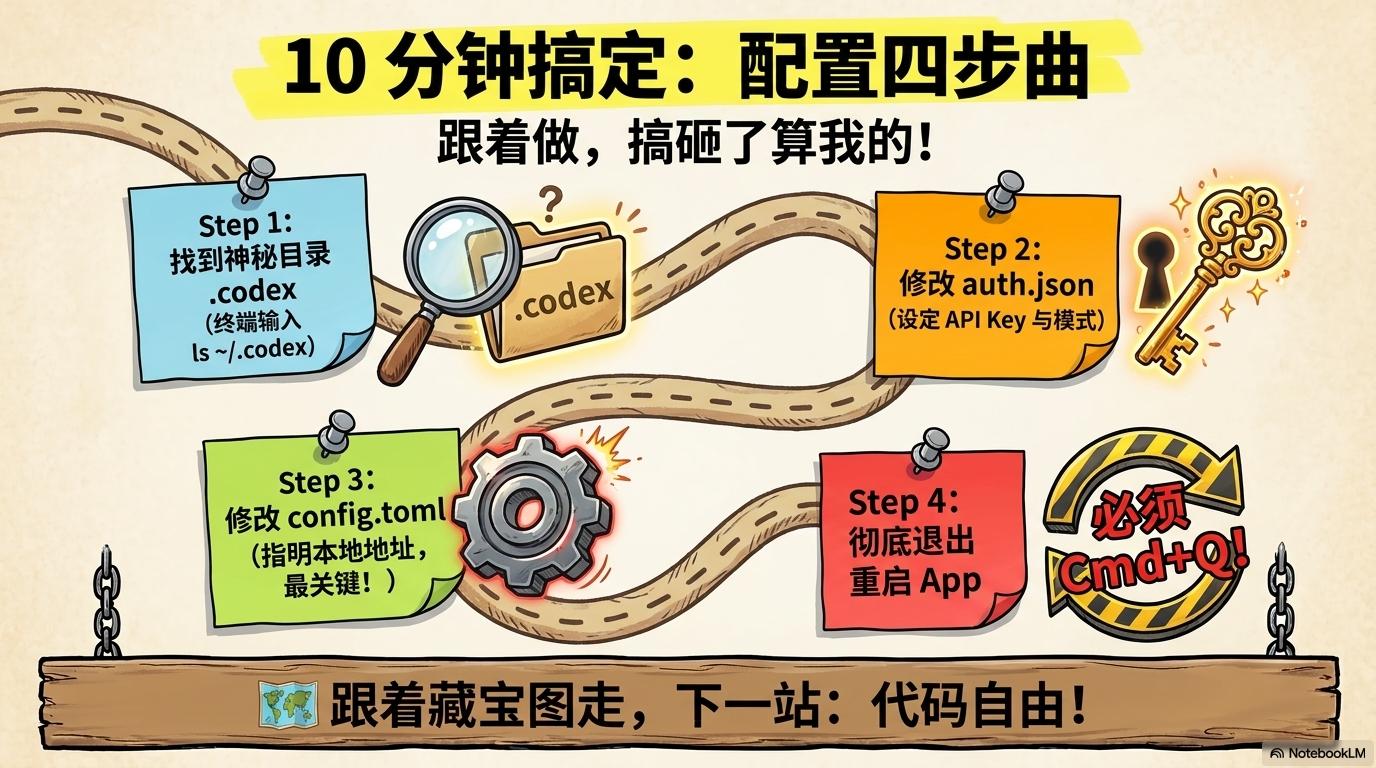
No matter which tool you choose above, the steps to configure Codex are exactly the same—you only need to modify two files.
Step 1: Locate the Codex Configuration Directory
All configuration files for Codex are hidden in the .codex folder under your user home directory:
| System | Path |
|---|---|
| macOS | /Users/your_username/.codex |
| Windows | C:\Users\your_username.codex |
macOS users can type ls ~/.codex in the terminal to see it. If the folder does not exist, launch the Codex App once to automatically create it.
Step 2: Configure API Key
In the .codex directory, find auth.json (create a new one if it doesn’t exist) and write the following content:
{
"auth_mode": "apikey",
"OPENAI_API_KEY": "your local model API-Key"
}
Different tools have different API Keys:
| Tool | API Key |
|---|---|
| omlx | omlx-2026-qwen36 (default key, can be viewed in ~/.omlx/settings.json) |
| Ollama | ollama (fixed value, Ollama’s key is always this) |
| LMStudio | leave blank or fill any string |
⚠️ Important: auth_mode must be set to “apikey”. This tells Codex to “authenticate using API Key, do not pop up the ChatGPT login window.”
Step 3: Configure Local Model Address (Key Step)
In the .codex directory, find config.toml (create a new one if it doesn’t exist) and add these configurations at the very top of the file:
For omlx:
model = "Qwen3.6-27B-4bit"
model_reasoning_effort = "high"
openai_base_url = "http://localhost:8000/v1"
For Ollama:
model = "qwen3.6"
model_reasoning_effort = "high"
openai_base_url = "http://localhost:11434/v1"
For LMStudio:
model = "the model name you loaded"
model_reasoning_effort = "high"
openai_base_url = "http://127.0.0.1:1234/v1"
Pay attention to a few details:
- The model must be the actual available model name in your local tool (check in the omlx/Ollama backend)
- openai_base_url must be at the top level of the file, not inside any [section] block
- The URL must end with /v1; missing a slash will cause issues
- Use http:// for local services; no need for https://
Complete configuration example (omlx):
model = "Qwen3.6-27B-4bit"
model_reasoning_effort = "high"
openai_base_url = "http://localhost:8000/v1"
[projects."/Users/tianxi"]
trust_level = "trusted"
# ... other configurations remain unchanged
After making these changes, just three lines of configuration.
Step 4: Restart Codex
This step can trip up many people:
- Ensure the local model service is running (do not close the terminal window for omlx/Ollama)
- Completely exit the Codex App. macOS users should press Cmd+Q to ensure there is no Codex icon in the Dock. Just closing the window is not sufficient; you must exit completely.
- Restart the Codex App.
- Create a new session and send a message to test.
If you receive a response normally, congratulations—Codex has connected to your local large model, and you can now use it for free and without limits.
Step 5: Verification (Optional)
If you are unsure about the configuration, you can test the local service’s reachability using curl in the terminal:
For omlx:
curl -s http://localhost:8000/v1/models \
-H "Authorization: Bearer omlx-2026-qwen36" | python3 -m json.tool
For Ollama:
curl -s http://localhost:11434/v1/models \
-H "Authorization: Bearer ollama" | python3 -m json.tool
If a list of models is output, it indicates that the Key and address are correct. If Codex still reports an error, it is likely due to a formatting error in the configuration; go back and check Step 3.
If you find the local model’s response too slow or its capabilities insufficient, don’t hesitate to switch to a third-party API proxy—just change one line of configuration.
Local Large Models vs GPT-5: What is the Real Difference?
Let’s speak frankly.
Local models at the Qwen3.6-27B level can achieve about 80-85% of GPT-4o’s performance in code generation tasks. For daily CRUD operations, bug fixes, script writing, and simple refactoring, it is completely sufficient.
The differences mainly lie in:
- Complex architecture design: GPT-5 better understands the overall architecture of large projects, while local models may occasionally have a limited perspective.
- Multi-turn dialogue consistency: In long contexts, local models may forget previous constraints.
- Code review depth: GPT-5 can identify more hidden bugs and security issues.
But think about it this way: 85% capability, $0/month, vs. 100% capability, $1400/month. For most developers’ daily usage scenarios, local models offer a far better cost-performance ratio than the official subscription.
Moreover—it’s free, and you can try it infinitely without worry. If you mess up, you can just start over without quota anxiety.
Frequently Asked Questions
Q1: Is 16GB RAM enough?

To be honest: 16GB running a 27B level model provides a very poor experience. Qwen3.6-27B-4bit quantized is about 14GB, macOS itself takes up 4-6GB, and the Codex App occupies another 1-2GB—16GB machines simply do not have enough memory, and the system will swap heavily (using the hard drive as memory), resulting in response times that will make you question your sanity.
Actual recommendations:
| Memory | Recommended Model | Experience |
|---|---|---|
| 8GB | 7B level (e.g., Qwen2.5-7B) | Basic coding assistance usable, limited capability |
| 16GB | 7B-14B level | Sufficient for daily coding, cost-effective choice |
| 24GB+ | 27B level (e.g., Qwen3.6-27B-4bit) | Smooth experience, recommended |
| 32GB+ | 27B level + larger context | Best experience |
If you have 16GB RAM, it is recommended to run a 7B or 14B model with Ollama, such as ollama pull qwen2.5:7b. Its capability is not as strong as 27B, but it is smooth and does not lag.
Q2: Why doesn’t the configuration take effect?

90% of the time, the reason is that openai_base_url is written in the wrong location. It must be at the top level of the file, not inside any [section] block.
Additionally, after modifying the configuration, you must completely exit the App and then restart (Cmd+Q); just closing the window is insufficient. Codex only reads the configuration once at startup.
Also, ensure that the local model service is indeed running—do not close the processes for omlx/Ollama in the terminal.
Q3: Still getting 401 Unauthorized?
- Check if the API Key has any extra spaces or line breaks (these can easily be introduced during copy-pasting).
- omlx users should check the API key settings in ~/.omlx/settings.json.
- Ollama users should confirm the key is “ollama” (in lowercase).
- Use the curl command above to test directly and confirm the key is valid.
Q4: How to switch back to the official subscription or third-party proxy?
To switch back to the official subscription: edit config.toml and delete or comment out the openai_base_url line (add # in front):
# openai_base_url = "http://localhost:8000/v1"
Then edit auth.json to change auth_mode back to “chatgpt”:
{
"auth_mode": "chatgpt"
}
Restart Codex, and the ChatGPT login window will pop up; you can log in normally by scanning the code.
Q5: What to do if the local model responds slowly?
- Ensure the model has been fully loaded into memory (the first request may be slow, but subsequent ones will be faster).
- Close other applications that occupy the GPU (like video editing software).
- Try using a smaller model (7B level responds faster).
- omlx users can adjust the context window size in model_settings.json; reducing the context can improve speed.
Q6: Can Windows users use it?
Yes, but with fewer choices. It is recommended to use Ollama (perfectly supports Windows) or LMStudio. Running local models on Windows requires an NVIDIA GPU with sufficient memory, and the experience is not as smooth as on Mac, but the functionality is identical.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.